데이터 모델링 종류
-
논리적 모델링
- 데이터의 개념 구조를 정립한다.
-
물리적 모델링
- 데이터베이스 구축에 필요한 제약조건이나 데이터 타입 등을 구체적으로 정한다. 어떤 데이터베이스를 사용하는 지에 따라서도 영향을 받는다.
-
데이터 모델링 순서는 아래와 같습니다.
- 논리적 모델로 먼저 개념 구조를 정의하고,
- 물리적 모델로 구체화 한다.
단순히 논리적 모델에 데이터타입 속성을 덧대기만 하면 물리적 모델이 되는 것이 아닙니다. 경우에 따라 논리적 모델에선 별도로 구분해놓은 Entity를 물리적 모델에서는 하나로 구성할 수도 있습니다. 이는 서비스의 속성과 상황에 맞추어 설계자가 판단합니다.
좀 더 세부적으로 나누면 ‘개념적 모델링’ 도 있으나, 이 문서에서는 생략하고 논리적 모델링과 엮어서 다룹니다.
Good DB vs Bad DB
- GOOD
- 고유하고 정확한 데이터를 저장하고 있음
- 빠르고 정확하게 데이터를 다룰 수 있음
- 데이터에 NULL이 없거나 적음
- 데이터가 늘어날 때 테이블 구조가 변하지 않음
- BAD
- 중복된 데이터, 틀린 데이터를 저장하고 있음
- 연산 실행이 오래걸리고 원하는 정보를 찾기 힘듦
- 데이터에 NULL이 많음
- 데이터가 추가될 때 테이블 구조가 변함
주요 용어 정리
- Entity
- 저장하고 싶은 데이터 대상 그 자체를 의미
- Table에서 row를 의미
(e.g. User Table에서 User 한 명의 정보를 말함)
- Attribute
- Entity에 저장하려는 내용
- Table에서 column을 의미
(e.g. User Table에서 Phone Number 정보를 말함)
- Entity Type
- 일반화한 Entity
- Relation(수학적 이론), Table(물리적 모델) 모두 Entity Type과 유사한 개념
- Relationship
- Entity 간의 관계, 연결점
*(주의)Relation Model은 Table로 표현한 모델을 말하며 Relationship과는 다름*
- Constraint
- Entity, Attribute, Relationship 간의 꼭 지켜야 하는 제약조건
- e.g.)
- Record는 두 개이상의 유저를 가질 수 없다.
- 휴대폰번호는 unique하다.
- User가 삭제되면 관련 Record도 삭제되어야만 한다.
- e.g.)
- Entity, Attribute, Relationship 간의 꼭 지켜야 하는 제약조건
데이터 모델링 방법론 적용
데이터 모델링에 ‘정답’은 없습니다. 방법론은 말 그대로 이론일 뿐입니다. 프로덕션에서는 각 서비스 요구사항과 상황을 고려하여 최적화된 모델을 사용해야 합니다. 방법론은 그저 최적화된 모델을 찾는 걸 도와주는 ‘생각의 도구’로서 활용합니다.
아래 예제로 사용한 모델들 역시 방법론을 이해시키기 위한 간단한 예시일 뿐 정답이 아닙니다. 서비스 특성에 맞게 가장 적합한 모델을 직접 설계해보는 것이 중요합니다.
1. 서비스의 모든 비즈니스 로직을 정의합니다.
- 데이터 베이스에 연관된 부분에 한하여 “모든” 비즈니스 로직을 정리합니다.
- 최대한 자세하게 적습니다. 정보 누락은 곧 버그라고 생각하고 누락되는 요소가 없도록 합니다.
- e.g.) 유저는 키워드와 후기로 장소를 평가한다, 후기와 키워드는 반드시 함께 작성되어야 한다. 유저는 장소를 평가할 수도 있고 안 할 수도 있다.
2. 정리한 로직에서 Database 요소를 찾습니다.
- 모델링의 시작은 Entity, Attribute, Relationship을 구분하고 정의하는 겁니다.
- 비즈니스 로직에서 해당 요소들이 될 수 있는 후보를 나열하고, 구체적으로 좁혀나갑니다.
- 아래는 후보를 쉽게 찾아내는 요령입니다.
- Entity 후보는 명사에서 찾습니다.
- Relationship 후보는 동사에서 찾습니다.
- Attribute 후보는 하나의 값으로 표현할 수 있는 명사에서 찾습니다.
- e.g.) 유저는 키워드와 후기를 작성해서 장소를 평가한다.
*Q.) 같은 명사 중에서 Entity와 Attribute를 어떻게 쉽게 구분 하나요?
A.) 키워드는 “편리한 대중교통”, 후기는 “물이 깨끗합니다.”와 같이 단일 텍스트(값)으로 표현됩니다. 이런 명사들을 Attribute 후보로 올립니다.*
구분한 요소의 후보들을 Attribute 없이 추상적인 레벨에서 표현하면 아래 그림과 같을 것입니다.
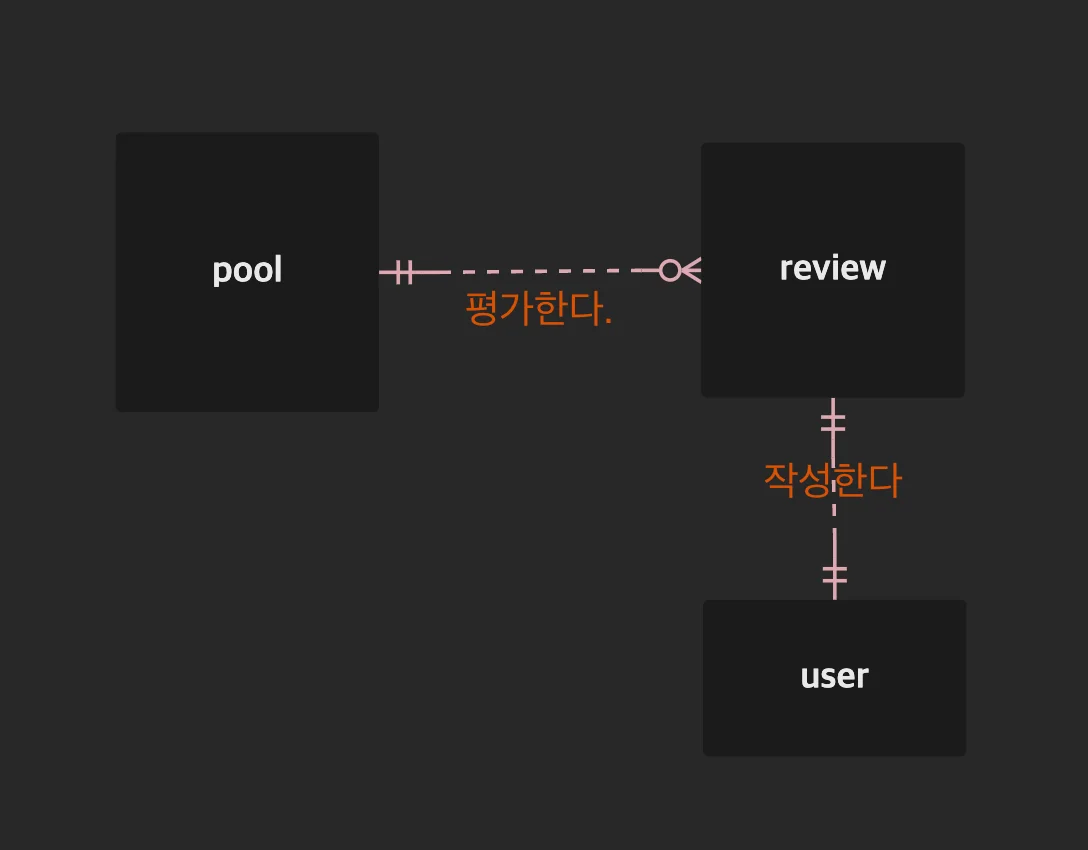
- 하지만 위에서 정리한 것은 말 그대로 ‘후보’입니다. 대부분 위의 요령으로 요소를 정리할 수 있지만, 프로덕션 서비스 상황에 당연히 예외를 둘 수 있습니다. 이는 설계자의 재량입니다. 하지만 합리적인 이유는 설명할 수 있어야 합니다.
- 예를 들어 위의 예시에서 “후기”는 단일 값으로 표현할 수 있는 명사니까 Attribute 후보로 올려두었습니다. 하지만 서비스 특성을 고려해봅시다. Product Entity에는 후기가 단 하나도 없을 수도 있고, 여러 개 있을 수도 있습니다. 위 요령으로 좁힌 Database 요소를 다듬지 않고 그대로 적용한다면 아래와 같은 구조가 될 것입니다.
e.g.) Product Table
| id | name | category | review_1 | review_2 | review_3 |
|---|---|---|---|---|---|
| 1 | 무선 이어폰 A | 전자제품 | ”음질이 좋아요." | "배터리가 오래가요." | "착용감이 편해요.” |
| 2 | 텀블러 B | 생활용품 | NULL | NULL | NULL |
- Product가 2개 있고 각각 리뷰가 3개, 0개 있다고 해봅시다.
- worst case에서
review가 가장 많은 상품의 review 갯수 * (총 상품 갯수-1)만큼의 NULL이 생깁니다. - 게다가 유저가 4번째 리뷰를 달면 column을 하나 늘려야 합니다. 서비스 정책으로 상품별 총 리뷰 갯수를 제한하고 있지 않다면, 위 구조에서 예상되는 Table의 column 갯수는 무한대입니다.
- 를 다시 한번 떠올려 봅시다.
- 좋은 DB는 NULL이 없어야 합니다.
- 유저가 NULL을 쓰지 않게 하거나, 클라이언트가 NULL을 보내지 않게 하거나, 서버가 NULL을 보내지 않게 하는 것이 아닙니다. DB 구조 그 자체로 NULL이 없어야 합니다.
*Q.) MongoDB를 쓰면 이런 고민 없이 효율적이고 유연하게 데이터 저장할 수 있는데요?
A.) MongoDB의 유연성은 그 유연성을 제대로 통제할 수 있는 운영 능력이 전제되어야 합니다. “유저가 NULL을 쓰지 않게 하거나, 클라이언트가 NULL을 보내지 않게 하거나, 서버가 NULL을 보내지 않게 하는 것”을 제대로 통제할 수 없다면 MongoDB의 장점도 제대로 활용하는 것이 아닙니다.*
예외사항까지 고려하면 “후기”를 Attribute 후보에서 Entity로 바꾸어 아래와 같이 개선할 수 있을 것입니다.
예외사항 적용 전
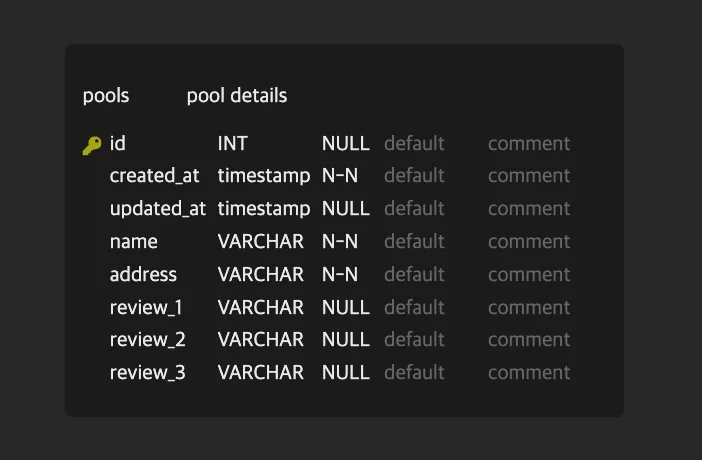
예외사항 적용 후

- 이렇게 후보를 나열하고 서비스의 특성을 반영한 예외를 적용하여 데이터베이스의 요소들을 정의합니다.
3. 정리한 로직에서 Constraint를 정의합니다.
- 위에 제시한 예제에서 ‘후기와 키워드는 반드시 함께 작성되어야 한다.’ 처럼 비즈니스 로직에 의해 DB 관리에 제약조건이 생기는 것이 Constraint입니다.
- Constraint를 고려할 때는 데이터베이스 이상현상이 없도록 하는데 초점을 맞춥니다.
- 데이터베이스 이상현상이란 데이터를 CUD할 때 제대로 동작하지 않는 걸 이야기합니다.
- e.g.) 서비스에서 특정 게시글이 삭제되더라도 유저의 북마크 목록에 반영되지 않는 문제가 생길 수 있습니다. DB 모델에 제대로 된 Constraint가 고려되지 않았거나, MongoDB의 유연성을 서버 로직이 완전히 핸들링할 수 있다는 가정에서 비롯되는 전형적인 이슈입니다.
- 데이터 모델링 단계부터 Constraint를 고려하면 이런 문제가 발생할 여지 자체를 없앨 수 있습니다.
- (1.)에서 나열한 비즈니스 로직 중 데이터베이스에 연관된 모든 Constraint를 나열하고 점검합니다.
- 그리고 여기까지 설계한 데이터베이스 모델이 이를 제대로 반영하고 있는지 점검하고, 만약 아니라면 수정합니다.
4. 데이터 모델을 정규화 합니다.
- 여기까지 과정을 거쳐서 설계한 데이터 모델을 다시 한 번 정규화합니다.
- 정규화(Normalization)한다는 건 (2), (3) 과정의 연장선이기도 합니다. 데이터 무결성과 고유성을 높이고, 데이터 이상현상을 없앱니다.
- 정규화 규칙은 많은 것이 있습니다. 함수 종속성같은 어려운 말로 이 규칙들을 정합니다만, 어려운 용어들은 걷어내고 일단 가장 중요한 아래사항들을 “차례대로” 점검합니다.
- 각 번호 순서대로 높은 우선순위를 가지며, 낮은 우선순위 규칙은 상위 우선순위를 만족하는 범위 내에서 지켜져야 제대로 “정규화”한 것입니다.
- Table의 모든 column 값 들은 같은 데이터 Type을 가져야 하며 더 이상 나눌 수 없는 단일 값이어야 한다.
-
Order Table 예제
id user_id items 1 1 { coffee: 2, sandwich: 1 } 2 2 { juice: 1 } -
user_id:1의 items는 coffee:2, sandwich:1로 나눠질 수 있습니다.
-
user_id:2처럼 데이터 형태에 따라 나눠질 수 있는 갯수도 다릅니다.
-
문자열과 숫자 타입이 혼재하고 있습니다.
-
따라서 위 예제는 우선순위 1번 조건을 만족하지 않습니다.
-
- 모든 Column에 Partial Dependency가 없어야 한다.
-
Review Table 예제
product_id user_id nickname review 2 3 ”alice" "배송이 빨라요” 7 10 ”bob123" "품질이 좋네요” -
Review를 특정할 수 있는 Unique 키를 만드는 조합은 (1) 어떤 상품(product_id)에, (2) 누가(user_id) 리뷰를 썼는가 입니다.
-
하지만 nickname은 (1),(2) 조합 중 (2) user_id만 있더라도 결정됩니다. 이런 column을 “Partial Dependency를 가지고 있다.” 라고 표현합니다.
-
따라서 위 예제는 우선순위 2번 조건을 만족하지 않습니다.
-
- 기본 Key 값(id)를 제외한 속성들 간 Transitive Dependency가 없어야 한다.
-
Order Table 예제
id zip_code city 1 06234 서울특별시 강남구 -
order_id를 알면 zip_code를 알 수 있습니다.
-
그리고 zip_code를 알면 city를 알 수 있습니다.
-
즉, order_id → city 뿐만 아니라, order_id → zip_code → city 도 동시에 성립합니다.
-
이렇게 기본키를 제외한 속성들 간 연결되는 종속성이 동시에 있는 것을 Transitive Dependency가 있다고 합니다.
-
따라서 위 예제는 우선순위 3번 조건을 만족하지 않습니다.
-
5. 다시 데이터 모델을 비 정규화 합니다.
- 비 정규화(De-normalization)한다는 건 위 정규화 규칙들에 위배되는 방향으로 정규화된 데이터 모델을 다듬는 것을 말합니다.
- 데이터 정규화 규칙들은 무슨일이 있어도 지켜야만 하는 신성불가침 조항이 아닙니다.
- 과도한 정규화는 오히려 데이터베이스를 무겁게 만들고, 서비스 성격에 따라 많은 연산으로 데이터 처리도 느리게 만들 수 있습니다.
- 예를들어 위에 설명한 제 1조건(
Table의 모든 column 값 들은 같은 데이터 Type을 가져야 하며 더 이상 나눌 수 없는 단일 값이어야 한다.**)**을 지키기 위해서는 전화번호 데이터 “010-1234-5678”도 010, ”-”, 1234, ”-”, 5678 로 분해해야 합니다. 더 엄격하게 지키려면 010도 0, 1, 0으로 더 잘게 분해할 수 있겠죠. - 그러나 대부분의 서비스에서 저런 레벨의 과도한 분해는 전화번호 데이터의 실제 쓰임새와 맞지 않아 전혀 의미가 없습니다.
- 예를들어 위에 설명한 제 1조건(
- 그래서 설계자는 정규화를 거친 데이터 모델을 다시 서비스 성격에 맞추어 일부분을 비 정규화 합니다.
- 하지만 꼭 명심해야 할 것이 있습니다. 정규화된 데이터는 “대부분” 데이터베이스의 품질을 향상 시킵니다.
- 그래서 데이터를 비 정규화 하기로 선택했다면, 정규화의 이점을 포기할 수 있는 납득 가능한 이유가 “반드시” 있어야합니다. 마치 위의 전화번호 예시처럼요.
- 힌트를 드리자면, “일반적으로” 비 정규화의 후보가 되는 데이터는 CUD보다 R(조회)의 성능 향상이 압도적으로 많이 필요한 데이터들입니다.
정리
- 위에 설명한 내용 외에도 데이터 모델링 방법론은 더 많고, 고도화할 수 있는 방법도 많다. 여기서 다룬 내용은 그중 실무에서 가장 핵심이 되는 부분들만 추린 것이다.
- 달리 말하면, 위에 설명된 내용은 상용 프로덕트 데이터베이스가 갖춰야 하는 “기본 중의 기본, 최소 조건”이다.
- 위 방법론을 따라 데이터 모델을 제대로 설계한다면 데이터베이스 관련 이슈의 90% 이상은 사전에 차단할 수 있다고 확신한다.
- 백문이 불여일견이다. 처음엔 어렵고 결과물이 더디게 나오더라도, 직접 설계해보는 것이 가장 빠른 학습이다.
댓글 (0)
아직 댓글이 없습니다. 첫 번째 댓글을 남겨보세요.